GenAI’s Shift: From Cyber Villain to LLM Protector

Don’t want to read? Then listen

Discussions about Generative AI (GenAI) in cybersecurity often veer toward its darker applications. The bulk of research churned out by the industry’s ‘prophets of doom’ focuses on the potential misdeeds of cyber villains using this tech. This doom and gloom narrative can be a bit of a bummer for cybersecurity defenders. To add to the challenge, it’s nearly impossible to identify if a cyber baddie is using GenAI to boost the sophistication or magnitude of their attacks. Even the wizards at OpenAI haven’t cracked the code to reliably sniff out AI-generated content.
… But the tides are turning…
I’m seeing a subtle emergence of reliable GenAI tools that benefit the defender. Specifically, the ability to protect LLMs from attacker manipulation. These solutions focus on either the input from a user or output from an LLM, ensuring they’re not malicious or accidentally dangerous.
Examples…
- Guardrails AI (documentation + presentation)
- Amazons “Comprehend”
- NVIDIA NeMo Guardrails (presentation)
- Simon Willison’s dual LLM model
- Exploding Gradients – RAGAS (OpenAI Devday preso)
- Meta’s Purple Llama

I like Caleb Sima’s approach (blog/preso) to separating LLM defenses into three buckets – firewalls (practical), dual LLM (experimental), and control tokens (futuristic).
Due to the firewall approach being the most practical of the three and the most likely to be deployed in production, we’ll focus our attention there.
LLM Evaluation
Every LLM firewall solution to some degree uses one LLM to evaluate the input or output of another LLM. When initially hearing about this idea, my main concerns were the reliability and accuracy of these evaluations.
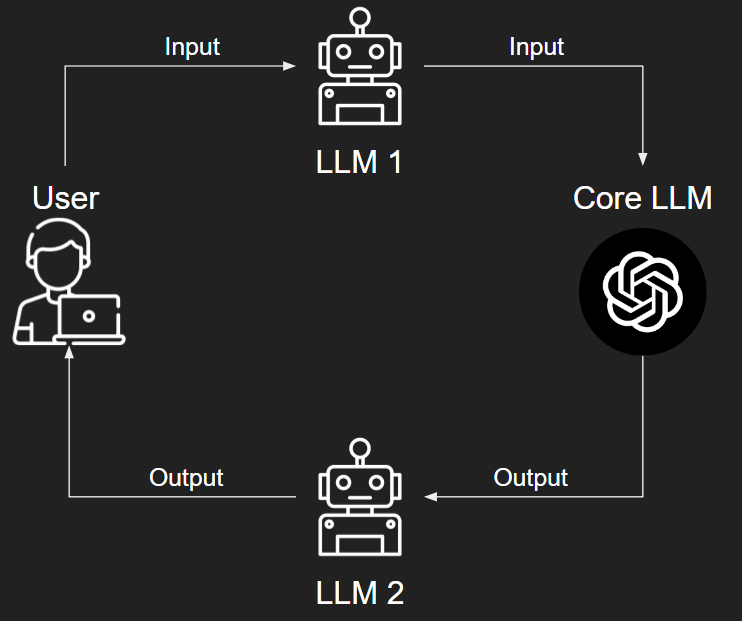
As you can see from above the flow is simple. We can have LLM firewalls evaluating the input from our user (LLM 1), the output from our core LLM (LLM 2), or both. What the LLM firewalls evaluate varies based on our interests. We can evaluate all kinds of stuff…
- Response accuracy (Databricks example)
- Response relevancy (RAGAS example)
- Reliability of the response (Databricks example)
- Safety of code (Meta example)
- Malicious intent (Meta example)
- Private data (Amazon and Guardrail AI examples)
- … And the list goes on …
But what about the accuracy of these evaluations? That’s where Meta’s recent Purple Llama announcement comes into play. They reliably evaluated the frequency an LLM generated insecure (94%) or malicious code. Also, they could detect potentially malicious outputs from LLMs that could be used in cyberattacks.
Evaluating the inputs and outputs of LLMs is still in the beginning stages, giving us plenty of room for improvement.
Looking forward
If a threat actor is committed they’ll figure out unique prompt injections to get around these LLM firewalls and successfully manipulate the core LLM. We’ll need more than LLM firewalls.
I want to leave you with a few futuristic defensive use cases for LLMs.
Control tokens
One systemic issue we’re facing with LLMs is that the control and data planes are merged. What does that mean? In traditional applications, there are different layers engineers can manipulate, protecting both the user and their application. Each layer has a different purpose, with a specific set of permissions (i.e. what they’re allowed to do). This is handy to prevent pesky injection attacks, such as SQL injection, cross-site scripting (XSS), etc.
But LLMs are special snowflakes, they’ve merged two of these layers into one, making it impossible to separate user input from system instructions. NVIDIA stated this well…
“At a broader level, the core issue is that contrary to standard security best practices, ‘control’ and ‘data’ planes are not separable when working with LLMs. A single prompt contains both control and data. The prompt injection technique exploits this lack of separation to insert control elements where data is expected, and thus enables attackers to reliably control LLM outputs.”
If you’re interested in learning more about this systemic issue listen to this part of Caleb Sima’s presentation. In this presentation, Caleb hints at a possible solution, which is “control tokens”. A token is simply a word (or part of a word) converted into an LLM-readable object. These special control tokens will be baked into the foundational LLM during training and will take priority over user input. Reaching the holy grail of separation between the control and data planes within LLMs.
Synthetic Voice Detection
Finally, I want to share a patent Google published that’s attempting to detect synthetic voices. If you’re not aware, cloning someone’s voice is easy. Like I only need 3 seconds of audio easy. Cloned voices can be used for all kinds of stuff, such as bypassing voice biometrics or impersonating executives to steal $35M.
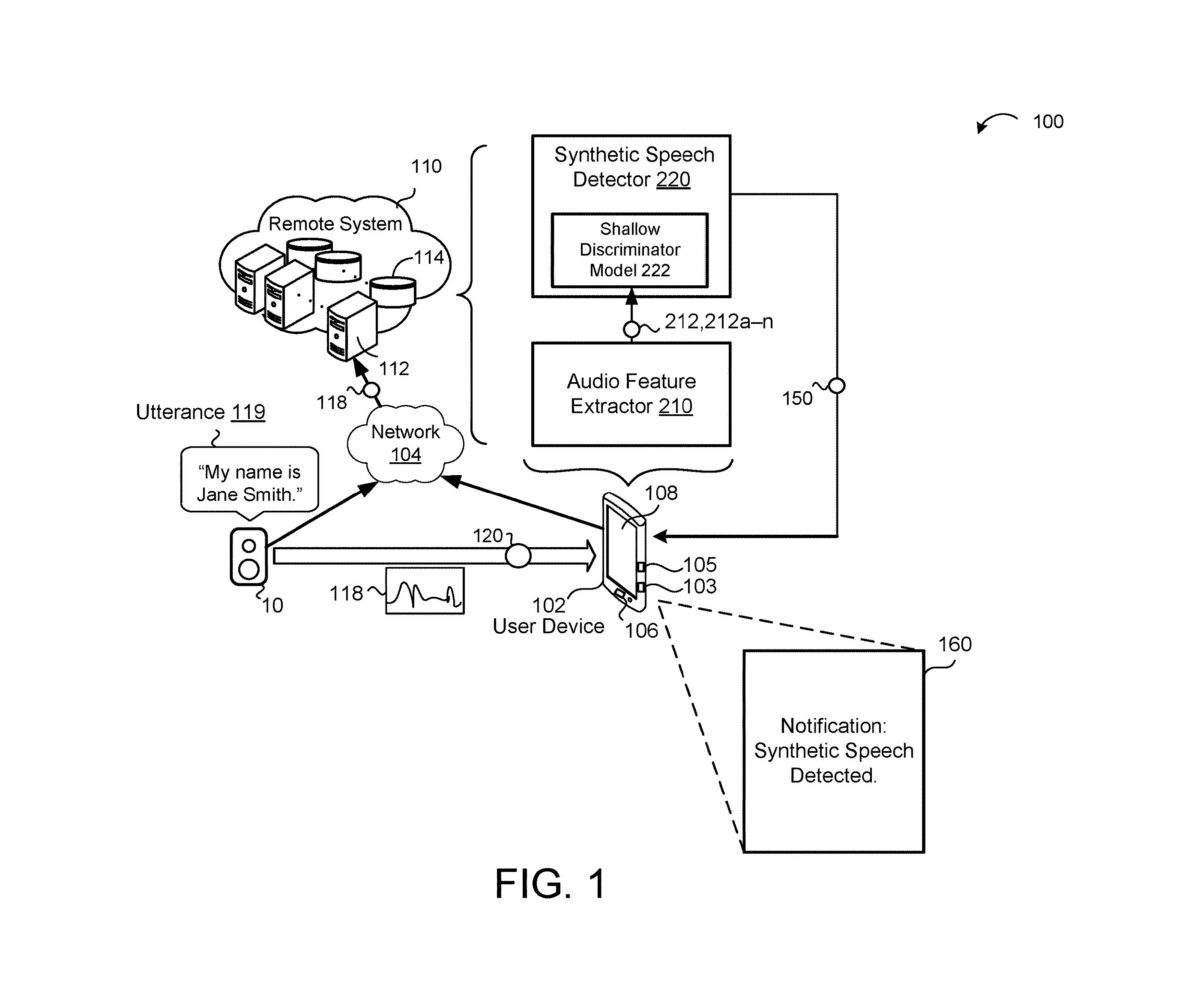
“Essentially, this system uses multiple AI models to detect whether speech it hears is synthetic or real.
First, a self-supervised model trained only on samples of “human-originated speech,” extracts features of a user’s audio input to make it easier for the next model to understand. That data is then sent to a “shallow discriminator model,” which is trained on synthetic speech. The second model scores the speech data to determine if it breaks a threshold of being synthetic or not.” (Patent Drop)
I’m hopeful that defenders will eventually have the sustained upper hand over attackers in a world of generative AI. I’m not alone in my optimism. Palmer Luckey agrees that GenAI will provide defenders with a home-field advantage against attackers.