TLDR: Lessons from 1 year of building with LLMs
This post is best consumed via video. I highly recommend taking the time to watch me chat about each one of these visuals instead of reading the descriptions below. I promise it’ll make more sense, and who knows, it might be a bit more enjoyable.
I read 42 pages of content, so you don’t have to. 🙂
Six practitioners who have been building with LLMs for a year published a three-part blog series covering the tactical, operational, and strategic lessons they’ve learned. It’s one of the most useful blogs I’ve seen for those looking to build with LLMs seriously.
My aim here is to make that series more accessible, creating a visual TLDR highlighting the most interesting parts (in my opinion).
The links for this series can be found here if you’re interested in reading it yourself. Part 1, part 2, and part 3. Additionally, the six authors presented their TLDR version of this series at the AI Engineer World’s Fair.
Let’s begin…
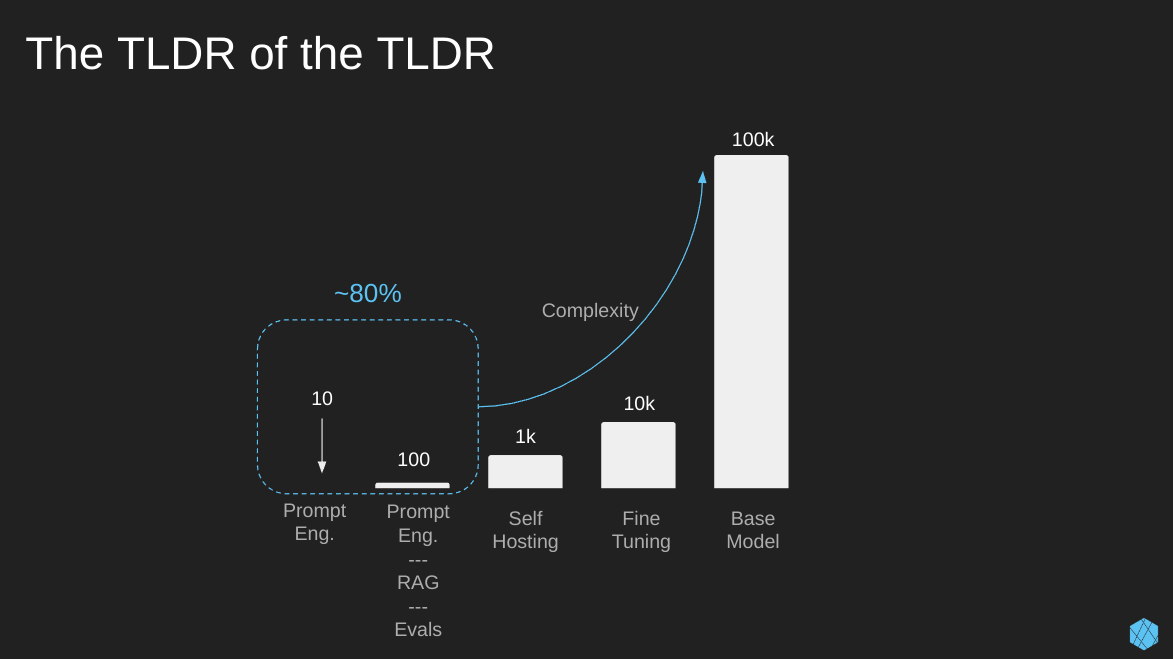
Here’s the TLDR of my TLDR.
So pay attention, if you take nothing else from this… Quality prompt engineering, RAG, and evaluations will get you ~80%—90% of the way to completing your task. There is no need to tinker with fine-tuning or create your base model from scratch.

As I mentioned previously, this blog series is divided into three chunks, covering tactical, operational, and strategic lessons learned. In this visual TLDR, I’ll focus most of my attention on the tactical stuff since that’s what most of you care about.
Also, note the little guiding icons in the upper right-hand corner. When an icon is bright white, that means we’re talking about lessons from that category.
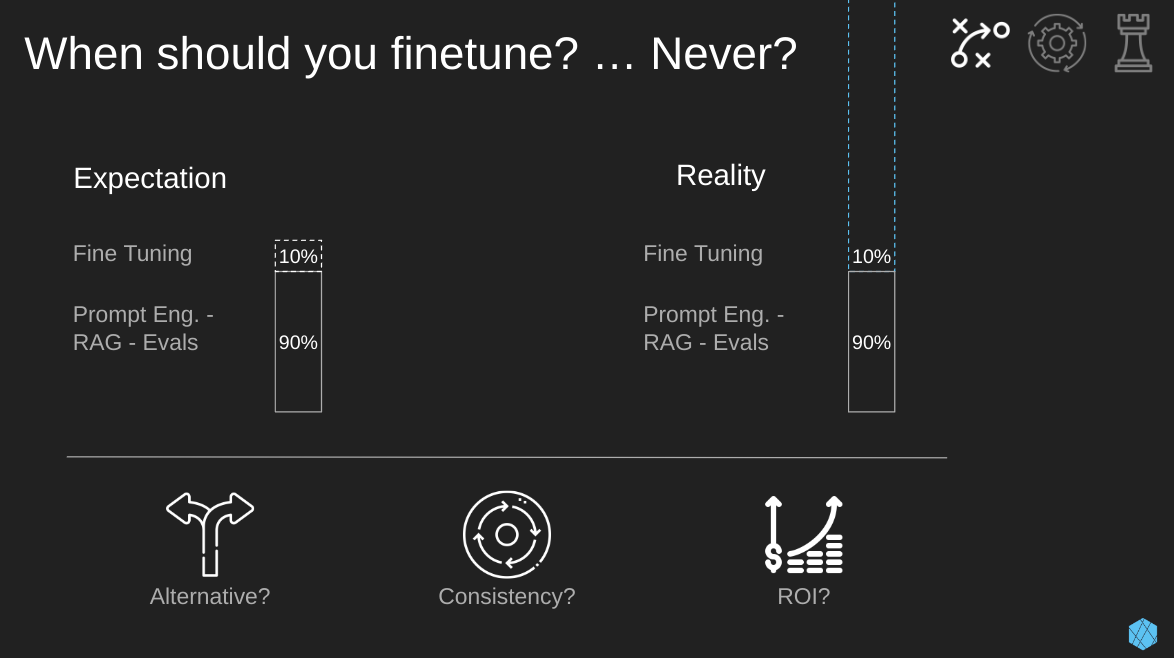
Since we mentioned the importance of avoiding unnecessary pain from complexity, I thought I’d start there.
Let me repeat this so you remember. For most use cases, Prompt eng., RAG, and proper evals will get you 80 – 90% to your goal. Often, fine-tuning is completely unneeded.
As many of you know, when building anything, squeaking out that last 10% is always the hardest to achieve… So, expectations are way off from what we experience in reality. That’s not just complexity but time and money.
If the fine-tuning gods still compel you, here are some questions you’ll want to ask before embarking on that journey.
- Alternative methods: Before starting the fine-tuning process, you should ask yourself… Have you tried all the alternatives, such as quality RAG, evaluations, and prompt engineering?
- Consistency: How critical is consistency in responses for your LLM? If you need the LLM to be consistent in almost every response (99%), then consider fine-tuning.
- ROI: Finally, we have the Mack Daddy of questions… Is there a convincing return on investment (ROI) for the amount of effort we’ll end up putting into fine-tuning? I.e., Is the use case we’re pursuing going to pay off in spades if we spend a huge amount of money and time on this last 10%?
… O! .. and to save money and time, start with synthetic data and bootstrap from open-source data where possible.
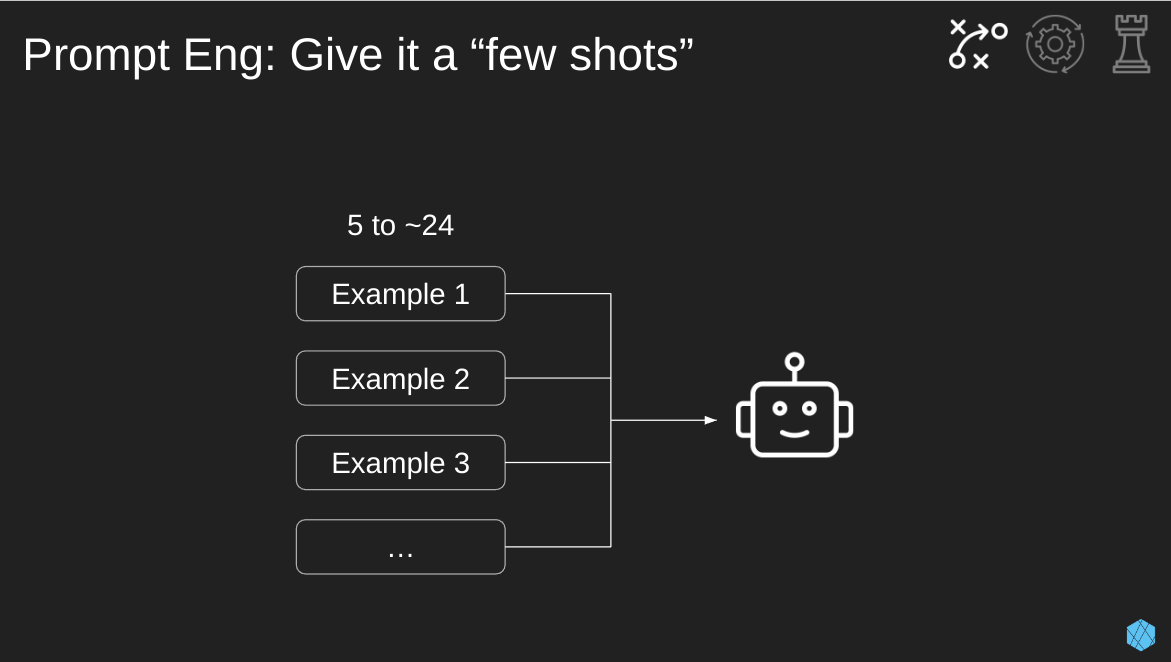
Now, let’s get into practical tips for prompt engineering.
Few shot learning is a go-to for many prompt engineers because it helps improve the LLMs output with minimal effort. The system prompt we’re putting into the LLM should contain examples of what an ideal output looks like. You don’t need to provide the full input-output pairs. In many cases, examples of outputs are enough.
Depending on the LLM task, if the number of examples you provided is too low, the model may over-anchor on those specific examples, hurting its ability to generalize. As a rule of thumb, aim for more than five examples, but don’t be afraid to go as high as a few dozen.
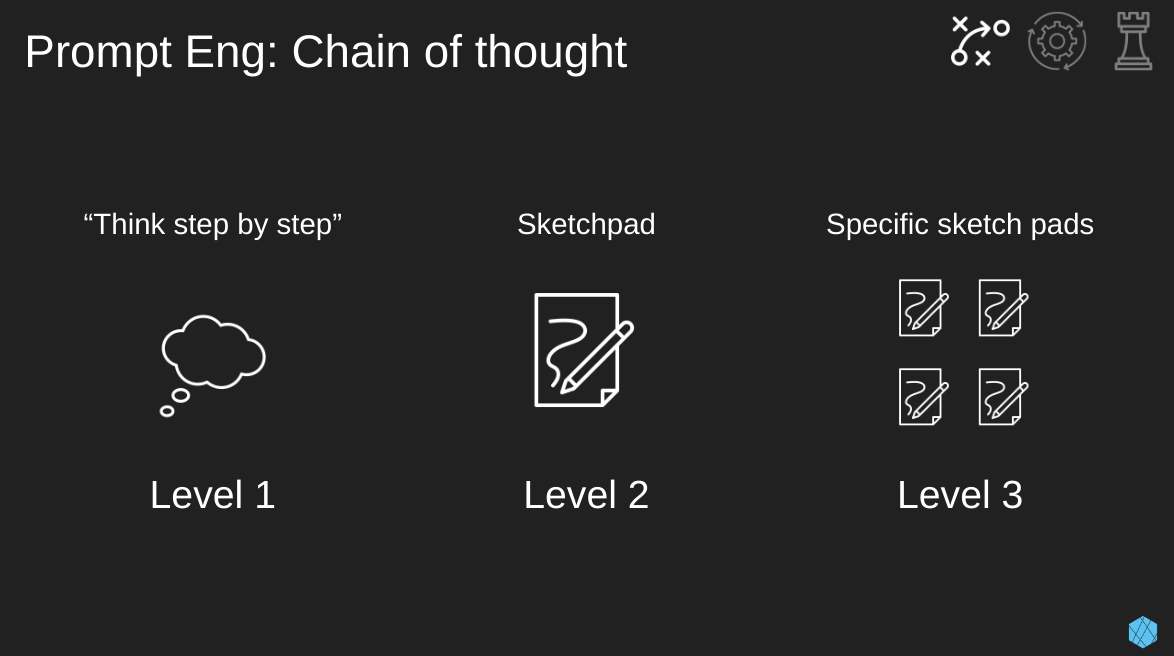
This is one of the most popular prompt techniques that improves the models about to reason is simply asking the model to think a little harder. This can be done in fancier and fancier ways.
- Level 1: The most basic approach is simply slapping “Think step by step” at the end of your prompt.
- Level 2: The next level asks the model to think through each step within the provided sketchpad or scratchpad using XML tags (e.g. <scratchpad>) before responding to the original question.
- Level 3: Finally, we have an advanced version where we ask the model to complete specific tasks within the sketchpad before responding to our original question. An example of summarizing a meeting transcript could be:
- First, list the key decisions, follow-up items, and associated owners in a sketchpad.
- Then, check that the details in the sketchpad are factually consistent with the transcript.
- Finally, synthesize the key points into a concise summary.

Our next prompting technique is using delimiters, or as I like to call it, setting boundaries. When you send a lot of data to a model and different parts of that data have varying purposes, the model will sometimes struggle. In this case, it’s best to ensure that your input and sometimes the model’s output have set boundaries using XML, JSON, or Markdown. GPT likes JSON and Markdown, while Claude prefers XML.
For example, say you’re inputting an entire report and derived insights from it into a model, and you want the model to treat them as separate things. In that case, you’ll want to separate them by boundaries so the model knows.
In some use cases, where one model’s output feeds into another model’s input, we want the model’s output to include boundaries as well. Luckily, there are Python libraries for commercial (instructor) and open-source (outline) models to assist with this.
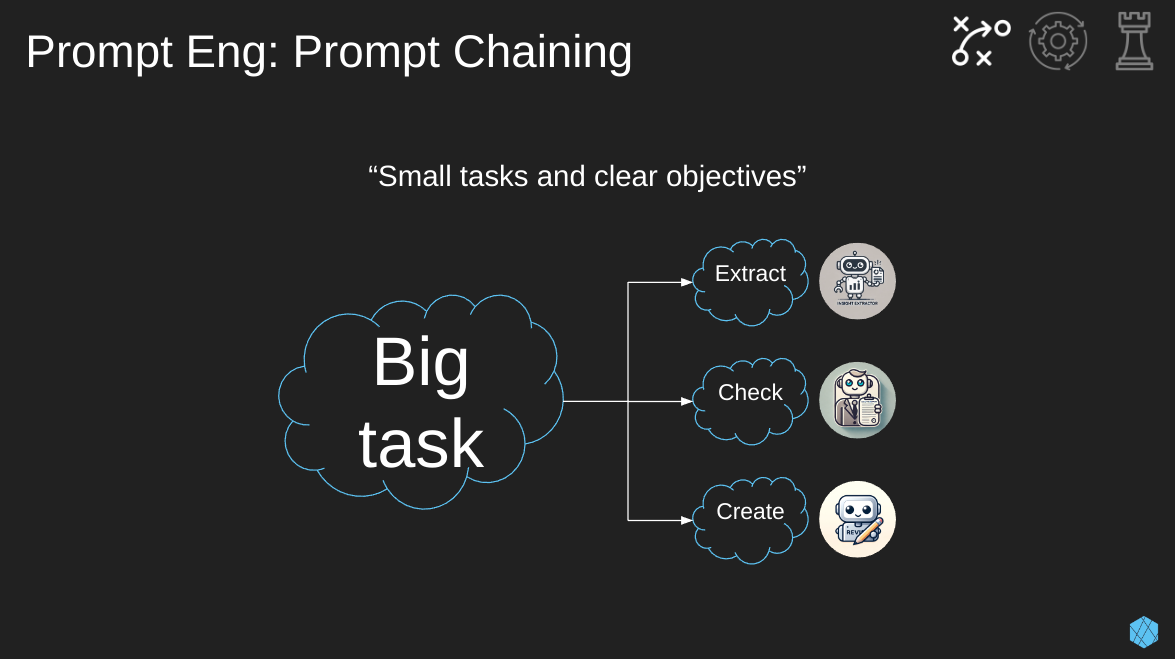
One of my new favorite prompting techniques is “prompt chaining”. This is where we break a larger task into small tasks with clear objectives.
Let’s go back to our meeting summarizer example. Instead of having a single, catch-all prompt for summarizing meetings, we can break it into steps:
- Extract key decisions, action items, and owners into structured format (XML, JSON, Markdown)
- Check extracted details against the original transcription for consistency
- Create a concise summary from the structured details
In the end, we’ve split a single prompt into multiple prompts that are each simple, focused, and easy to understand. An additional bonus is that we can now iterate and evaluate each prompt individually.
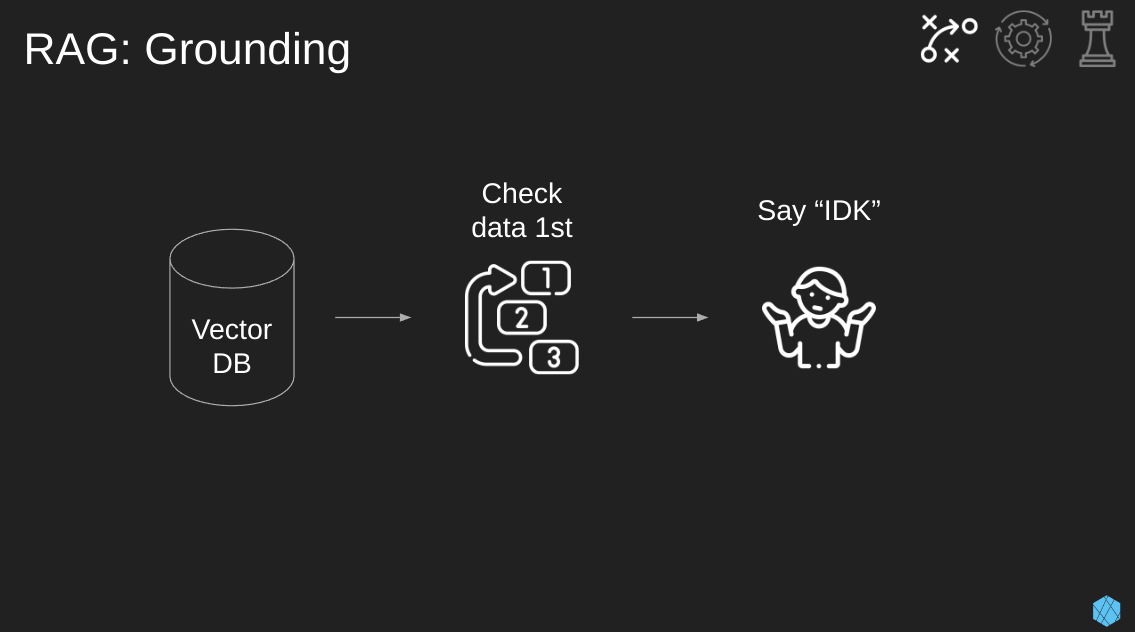
Let’s move onto retrieval augmented generation (RAG) setups.
One of the primary benefits of using RAG is the concept of “grounding.” Grounding is when we prompt the model to solely use the data from our RAG documents and nothing else. If the model doesn’t know the answer, it should respond with “I don’t know.” This prevents the model from making something up or reaching out to the Internet and finding an irrelevant answer.
This simple step can lower the number of hallucinations coming out of your LLM. But! Know that you’ll never get rid of all hallucinations. The best LLM providers still have at least 2% hallucinations.

There was a moment when vector databases were all the rage, and many n00bs (including me) thought they’d completely replace traditional DBs for all LLM use cases. This is wrong; they both have their place in the new LLM world.
It’s important to know that a vector database is good at semantic search, which isn’t relevant for all LLM use cases. They can search for vague items such as synonyms, hypernyms, spelling errors, and multimodality (images).
When it comes to exact text matches, keyword search is a much better fit due to the consistency, quality, cost, and speed of the response. These include nouns, acronyms, and specific IDs.
When setting up your RAG architecture, know that it’s about “AND”, not “OR”. We should use both shiny new vectors and traditional NoSQL databases to improve our LLM products. Here’s a detailed example of a production RAG system using both.
Most of the cool tech bros and gals have spent a lot of time talking about the importance of evaluations in the past 6 months or so.
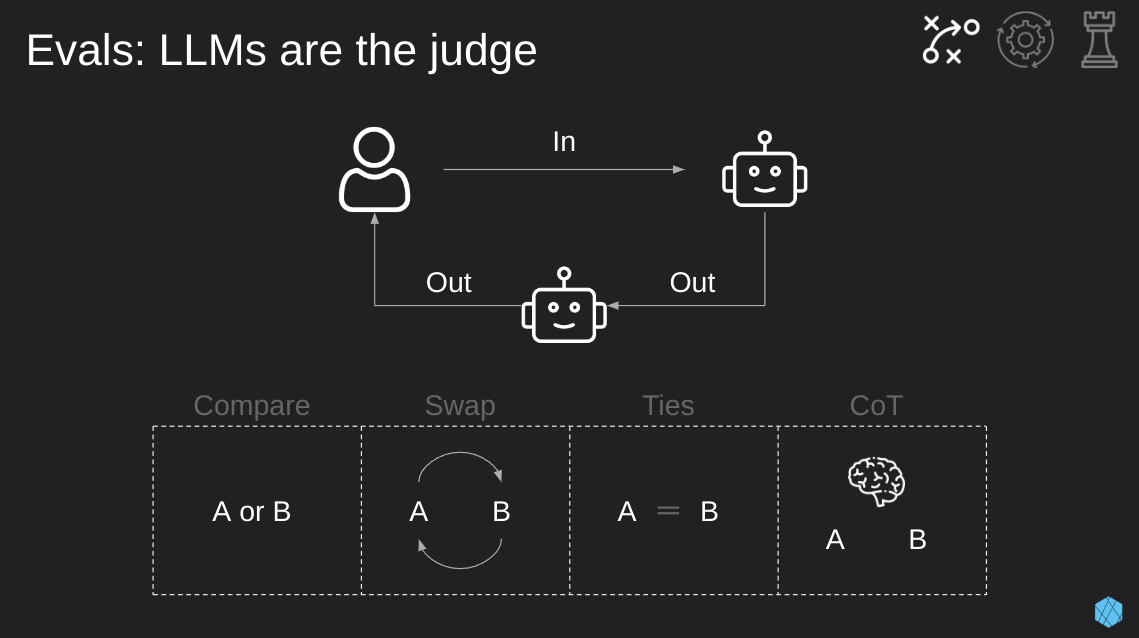
Evals are a common way to quickly improve the outputs of your LLM. The purpose of an eval is to rate the output of a model over time to see what adjustments improved its performance. This can be done manually with humans, but that’s time-intensive and expensive. A low-cost way to do this with pretty good results is to use another LLM as the judge.
The LLM will review the outputs continuously over time to see how they’re performing, and then humans can review these results periodically to see if performance is improving or declining.
There are many ways to mess this up, so here are four considerations when setting an LLM as a judge.
- Compare: Instead of asking the LLM to score a single output, present it with two options and ask it to select the better one. This leads to more stable results.
- Swap: The order of options presented can bias the LLM’s decision. To mitigate this, do each comparison twice, swapping the order of pairs each time. Just be sure to attribute wins to the right option after swapping!
- Ties: In some cases, both options may be equally good. So, allow the LLM to declare a tie so it doesn’t have to arbitrarily pick a winner.
- Chain-of-Thought (CoT): Asking the LLM to explain its decision before giving a final preference can increase reliability. As a bonus, this allows you to use a weaker but faster LLM and still achieve similar results. Since this part of the pipeline is often in batch mode, the extra latency from CoT isn’t a problem.
Alrighty! We’ve gotten past all the interesting tactical lessons learned; now, let’s look at the operational ones.
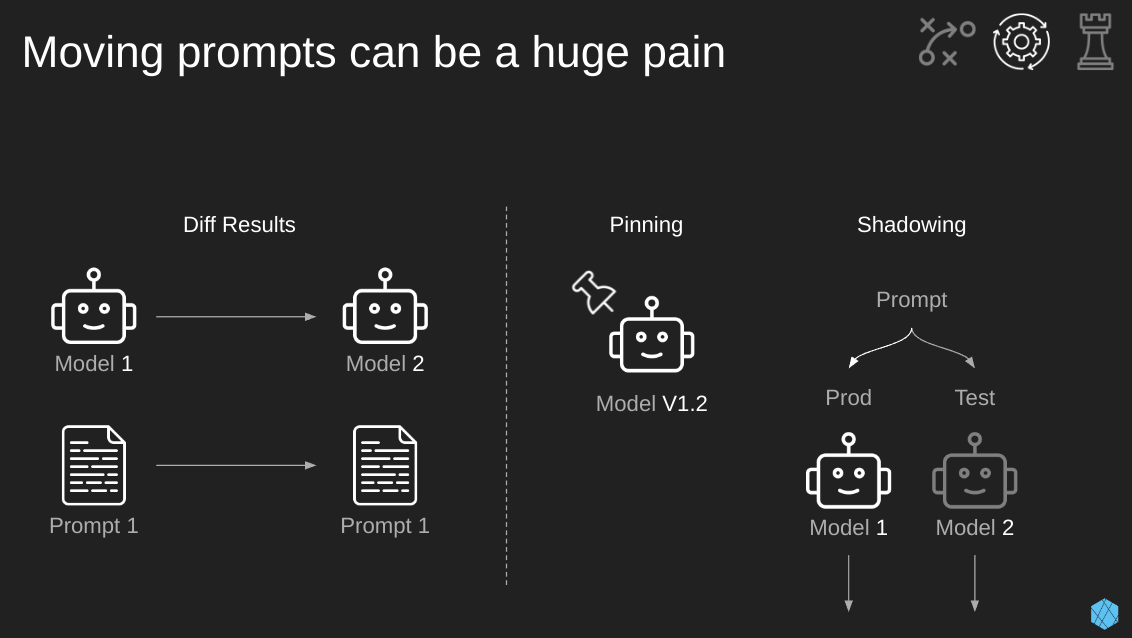
When moving a prompt from one model to the next, you can get dramatically different results. This applies to the same model provider as well, such as upgrading from GPT 3.5 to GPT 4.
This change can work in your favor, improving the performance, but sometimes it’ll work against you, providing worse answers.
There are some tricks we can use to mitigate the downfalls of model swapping:
- Pinning (short-term): Instead of switching, we’ll just stay put through “pinning”. Some commercial model providers give the option of “pinning”, where you pin a specific version of a model so that when an upgrade happens, your model doesn’t change. This approach is nice for the short term, but we all want those juicy gains from upgraded models, so we have another approach…
- Model Shadowing (longer-term): This is when our production model runs normally, but in our “test” environment, a different model runs with the same prompt. During this process, we’ll evaluate the outputs of the same input over time through these different models, ensuring that the new model’s performance doesn’t decline. If we’re happy with this, we can then switch to the newer model in production.

The ideal GenAI UX is still being figured out and evolving, but often, we want to place a human in the loop to improve our output over time. Human feedback can train future versions of the model, improving their overall experience. This feedback can be received either explicitly or implicitly. I prefer implicit over explicit due to users not wanting to explicitly provide feedback consistently… And often, actions speak louder than words.
Here are a few examples of implicit and explicit.
- Implicit
- Coding assistants: Where users can accept a suggestion (strong positive), accept and tweak a suggestion (positive), or ignore a suggestion (negative)
- Midjourney: Where users can choose to upscale and download the image (strong positive), vary an image (positive), or generate a new set of images (negative)
- Explicit
- Chatbots: Where users can provide thumbs up (positive) or thumbs down (negative) on responses or choose to regenerate a response if it was really bad (strong negative)
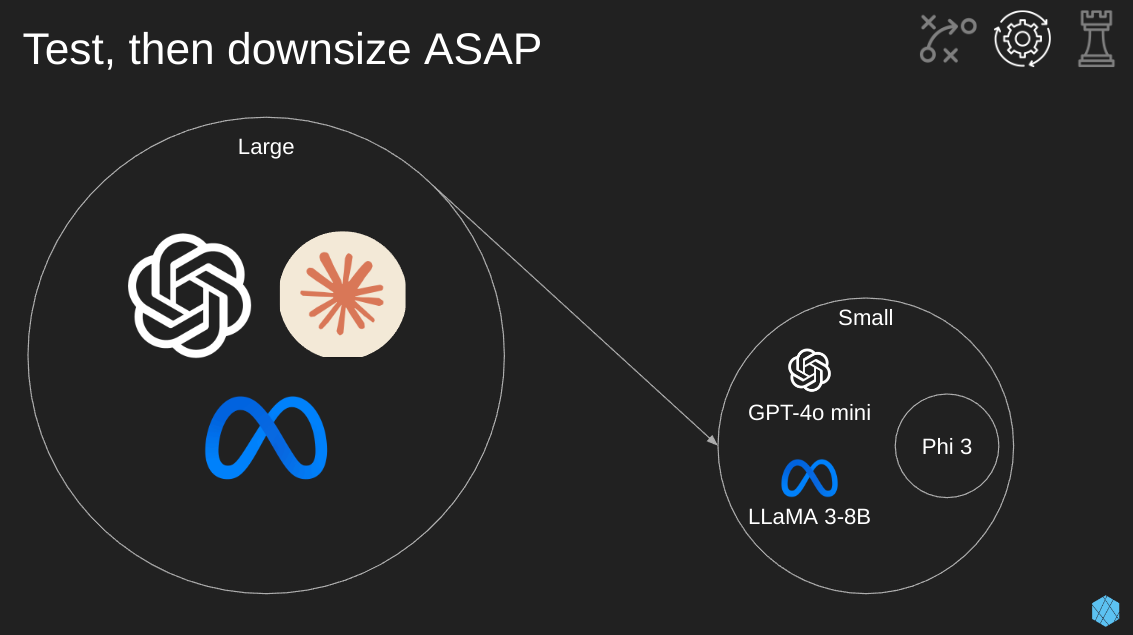
When exploring ideas for new products or features, many companies start with large models from the big LLM players. Think Google’s Gemini, OpenAIs GPT, Anthropics Claude, and Meta’s Llama. The trick is to remember… As soon as you prove it’s possible to complete a task with an LLM, immediately jump down to a smaller model. This will save money and latency.
Another way of viewing the importance of downsizing models is increasing profit margins.
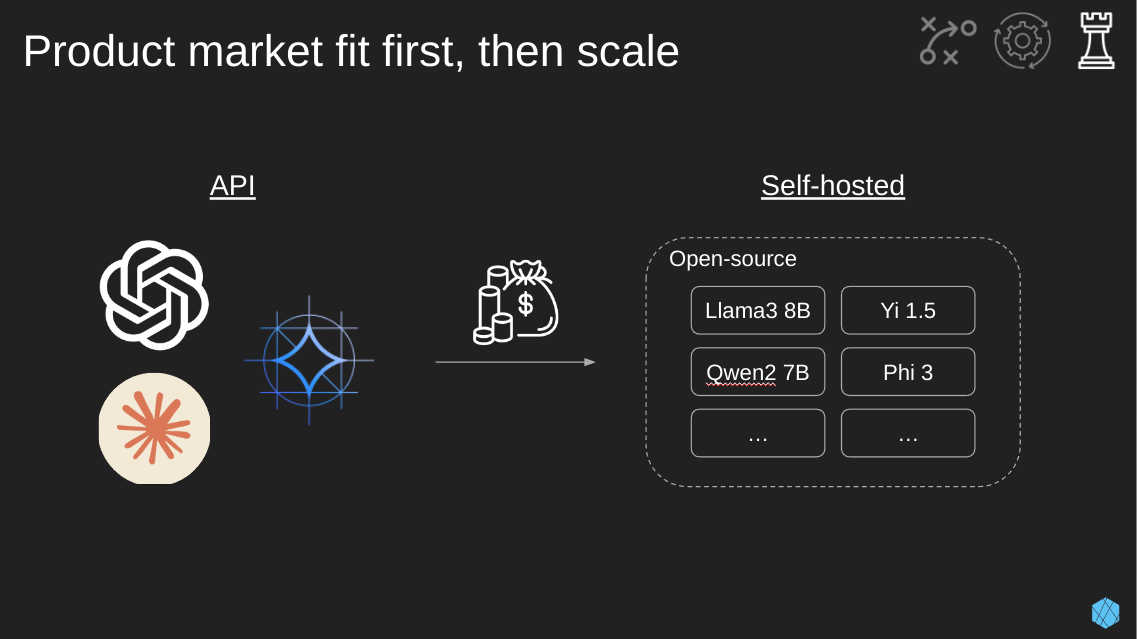
The primary goal of any new product or product feature should be finding product market fit. Once you’ve established that people are interested in using your new shiny LLM-enabled widget, it’s time to scale, lowering cost and improving the end user experience, such as reducing latency.
Establishing an LLM’s ability to complete a task and product-market fit will likely come from large models that are easy to set up via simple APIs. Once we start racking in the money, we should figure out how to lower our costs and increase that sweet profit margin. The margin increase is going to come from self-hosting smaller open-source models that we can tailor to our specific jobs.
Some options today (it’ll change tomorrow) are Phi 3, Yi 1.5, Qwen 2 7B, or Llama 3 8B.

This final slide is one of the most important due to the common misconceptions companies have about their strategic moats.
For teams that aren’t building models (almost all of you), the rapid pace of model innovation is an overwhelming gift. The relative ease of migrating from one state-of-the-art model to the next to chase gains in context size, reasoning capability, and price-to-value is a beautiful thing. This progress is as exciting as it is predictable.
But! … Don’t mistake the ability to quickly swap out models as a durable moat for your company.
Instead, we need to focus our efforts on creating quality processes and infrastructure such as:
- Evaluation: To reliably measure performance on your task across models
- Guardrails: To prevent undesired outputs no matter the model
- Caching: To reduce latency and cost by avoiding the model altogether
- Data flywheel: To power the iterative improvement of everything above
These components are what create durable products and, in turn, companies.