Three GPTs Walk into a Bar and Write an Exec Summary

Don’t want to read? Then listen

Today I want to share a process around three Custom GPTs I’ve created that work together to help you create more meaningful executive summaries. The first GPT extracts insights, the second crafts executive summaries, and the third revises the previous write-up.
These Custom GPTs are meant for high-frequency or short turnaround timeframes. A common example would be when your boss asks for a summary of (X) event, technology, or trend, and you have a few hours to respond. But! Before jumping into this process, let’s take a quick detour into writing.
On Writing
Writing is hard, like really hard. If you’re writing at a consistent pace, you’re bound to hit the blank page, which is a scenario many writers dread. Myself included. As Stephen King put it…
“The scariest moment is always just before you start.”
I’m facing it right now, and we all face it eventually.
Even if you don’t consider yourself a “writer”, you are. Anytime you’re writing documentation, responding to an email thoughtfully, writing speaker notes for a presentation, and many other subtle forms of writing…. You’re behaving as a writer.
I often preach to friends and family the importance of writing for a single reason, critical thinking. For me, writing is a form of thought, and thankfully, Jordan Peterson (and many others) have reaffirmed my long-held belief multiple times. But writing doesn’t come easy. It’s a craft that’s honed over many years of intentional practice. The word “intentional” is key.
We now live in a world where LLMs can write for us, which for many people, is their avenue to avoid having to write in any meaningful way going forward. Even though we can use LLMs it doesn’t mean we should always default to them. Currently, there’s a time and place for using LLMs.
I’m obviously not a doomer who thinks LLMs are the end of society’s ability to think critically, that ship has already sailed with the advent of social media (JK… Kind of). My intent with this post is to share a process that assists in writing for time-constrained “asks.”
Remember, improved writing leads to improved thought, so don’t always default to using LLMs for your writing endeavors.
Prompting Magic
I’m a prompt engineering n00b, so many of my learnings from creating these custom GPTs may seem obvious to some but hopefully insightful to most.
The naive approach to creating a prompt would be asking a model to “write an executive summary based on what the user provides” or something similar. I’ve tried this and many other naive approaches. The results are pretty good but nowhere near as good as they could be with some minor prompt engineering techniques.
The resources I found most helpful while embarking on this prompt engineering journey were:
- Prompts Guides: Prompting Guide AI, OpenAI’s Prompt Guide, and Eugene’s post on prompting fundamentals
- Easy button: Claude’s Prompt Generator
Anthropic, the creators of Claude, recently created an easy button for prompt creation via their new “Prompt Generator”. This is a game-changer. All you need to do is type out what you want the LLM to do in as much detail as possible, paste that into the generator, and BOOM! You have an improved prompt with many of the techniques I’ll share below already included. This tool is pay-to-play, so you’ll need to purchase API credits. The generator is useful and I recommend trying it, but you’ll still need to understand the “why” behind the prompting techniques so you’re able to iterate over time. And trust me, you’ll make many changes to the generated prompt, so it fits neatly into your use case.
The above sources offer plenty of information, but we want to use specific tricks to write executive summaries. I’ll briefly walk through the relevant tricks, but if you’re interested, check out the sources above.
Avoid negative words: When prompting models, we want to avoid negative words such as not, never, no, etc. Instead, we want to focus on specificity, narrowing in on exactly what we’re looking for.
Example
Bad example: The following is an agent who recommends movies to a customer. DO NOT ASK FOR INTERESTS OR PERSONAL INFORMATION.
Better example: The following is an agent that recommends movies to a customer. The agent is responsible for recommending a movie from the top global trending movies. It should refrain from asking users for their preferences and avoid asking for personal information. If the agent doesn’t have a movie to recommend, it should respond, “Sorry, couldn’t find a movie to recommend today”.
Use delimiters: Use delimiters to clearly separate parts of your input. Using triple quotation marks, XML tags, section titles, etc. can help separate sections of text, ensuring the LLM treats each differently.
Example
System Prompt: You will receive a pair of articles (delimited with XML tags) about the same topic. First, summarize the arguments of each article. Then indicate which of them makes a better argument and explain why.
User Input:
<article> insert first article here </article>
<article> insert second article here </article>Specify length: Specify the output length you’re looking for from the LLM. The targeted length can be specified in terms of the count of words, sentences, paragraphs, bullet points, etc. However, instructing the model to generate a specific number of words does not work as well as the number of paragraphs or bullet points. I’m not sure why models struggle so much with word count; my guess is that it’s related to reasoning and their generative nature.
Example
Summarize the text delimited by triple quotes in 2 paragraphs. """insert text here"""Encourage the model to think: A common technique used for improving a model’s ability to reason is called “Chain-of-thought” (CoT). The most basic version of this would be to add “Think step by step” at the end of your prompt, but we can do better. A fancier way of doing this that provides a better output is using a “scratchpad”. In this case, we’re requesting the model contain the CoT within a designated <scratchpad>, and then generating the <summary> based on that <scratchpad>. This makes it easier to parse the final output, improves the writing quality, and sometimes reduces hallucinations.
Example
Claude, you are responsible for accurately summarizing the meeting <transcript>.
<transcript>
{transcript}
</transcript>
Think step by step on how to summarize the <transcript> within the provided <sketchpad>.
In the <sketchpad>, return a list of <decision>, <action_item>, and <owner>.
Then, check that <sketchpad> items are factually consistent with the <transcript>.
Finally, return a <summary> based on the <sketchpad>.Break big tasks into subtasks (i.e. prompt chaining): Finally, we have the most important technique mentioned in all three guides listed above, which is breaking complex tasks into smaller tasks. This is the reason I have three custom GPTs instead of a large one. By dividing up the duties to specialized GPTs, we can get better results, and if you intend to scale, you’ll likely save money on inference using this trick with smaller specialized models. The process is simple, after breaking a large task into subtasks, we prompt the LLM with a subtask, and then its response is used as input to another prompt. This is called “prompt chaining”, where a task is split into subtasks, and we create a chain of prompt operations.
An example cartoon is below; see examples here, here, and here.
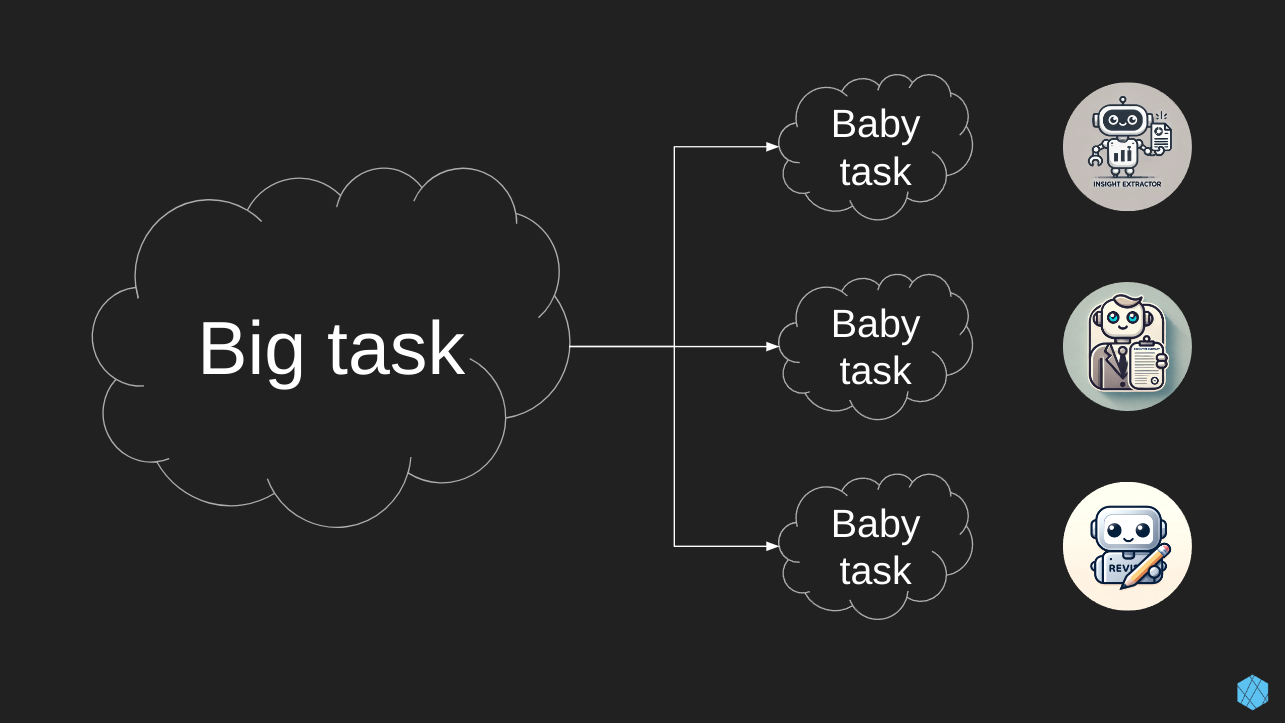
Franken-GPT
I’ll provide a high-level explanation of what I created and how to use it, but the best way to understand is to interact with the GPTs and read the system prompts. Of the two options I’d say reading and modifying the prompts is the more important. The Custom GPTs have a short shelf life because I’ll likely continue updating the system prompts over time, but more importantly, you can take these system prompts to use them wherever you’d like. For example, not everyone will have access to ChatGPT, so you can take the prompts and use them in other commercial models (Claude) or open-source models (Llama).
We’ll start with the resources first, then jump into the process.
Custom GPTs (Sign up to ChatGPT to get access)
- Insight Extractor: focuses on extracting the top 10 most unique insights from a report.
- Exec Sum Writer: Writes a four-paragraph executive summary from the 10 insights and the full report text.
- Revisor Bot: Revises the initial executive summary, aiming to improve brevity, clarity, and readability.
As you can see, there are three GPTs: Insight Extractor, Exec Sum Writer, and Revisor Bot. We use these GPTs in that order.
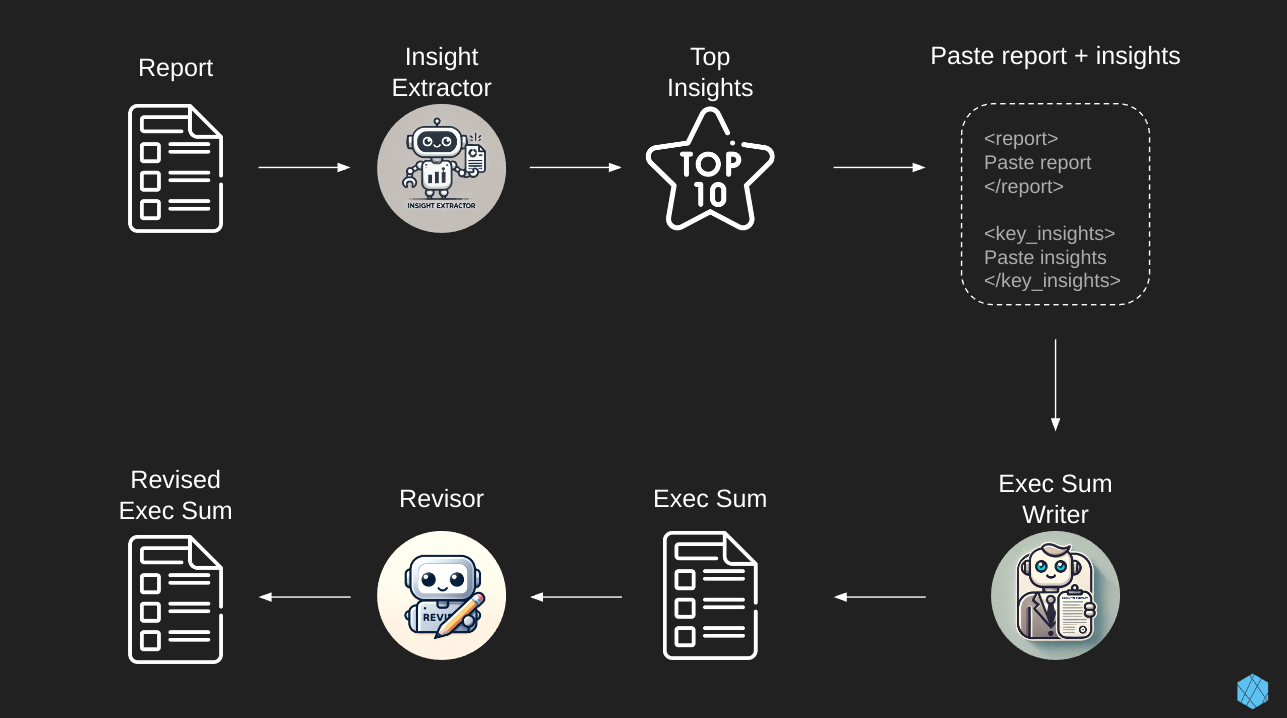
To begin, find a report you’d like to create an executive summary for, then copy/paste the text from that report into the Insight Extractor. You’ll see the Insight Extractor reasoning through what’s most interesting in that report via its <scratchpad>. Once it’s finished thinking, it’ll spit out 10 of the most impactful insights.
Next, we’ll copy/paste that output into the next GPT, the Exec Sum Writer. This step is a bit tricky because we’re relying on the delimiters I mentioned previously. To do this correctly, you’ll want to structure your input like this…
<report>
Paste the report text here.
</report>
<key_insights>
Paste the top 10 insights here.
</key_insights>Afterward, you’ll see that the Exec Sum Writer has created a four-paragraph executive summary. Now we can paste that into the Revisor Bot, which focuses on improving the brevity, clarity, and readability of the initial executive summary.
Boom! You’ve created your first automated executive summary.
This is the beginning, not the end. I recommend double-checking for hallucinations and making edits to the final output, so you’re tailoring each executive summary to fit your tone.
Until next time you beautiful people!